
Google opravil AI generátor obrázků. Imagen 3 už obrazovou kvalitou předčí DALL-E

Zdroj: Imagen 3, repro Petapixel
Google ve vývoji AI operuje ve stylu „pozdě, ale pořádně“. Připomínka, že má tato minimálně z první půlky nedobrovolná taktika své výhody, přišla letos v únoru, když uvedl svůj AI nástroj pro tvorbu obrázků Imagen. Tehdy čelil zesměšnění, když i u historických postav dosazoval mylně černochy, a to třeba i mezi generály Konfederace v americké občanské válce, kteří ve skutečnosti bojovali za zachování otroctví. Nyní chce složit reparát se značně vylepšeným modelem Imagen 3.
Google slibuje možnost generovat „obrázky s ještě lepšími detaily, bohatším osvětlením a menším množstvím rušivých prvků. než naše předchozí modely. „Výrazně jsme zlepšili schopnost modelu Imagen 3 porozumět promptům, což pomáhá modelům generovat širokou škálu vizuálních stylů a zachytit drobné detaily z delších promptů," říká.
„U Imagen 3 jsme dosáhli významného pokroku v poskytování lepšího uživatelského komfortu při generování obrázků lidí," uvedl v tiskové zprávě manažer Googlu Dave Citron. Původní Imagen měl problémy vykreslit jako bělochy třeba tzv. zakládající otce USA nebo papeže.
New game: Try to get Google Gemini to make an image of a Caucasian male. I have not been successful so far. pic.twitter.com/1LAzZM2pXF
Záhy Google vpynul možnost zobrazovat lidi jako celek a tato ukázka „AI nedostatečnosti“ tehdy způsobila i propad o hodnoty společnosti o pěkných pár miliard na burze. Nyní se Google jistí tím, že nedovoluje vykreslovat reálné postavy. A jistou brzdou proti deepfakes mají být i limity v zobrazování politických nebo kontroverzních témat. Podobné zábrany má v sobě přitom DALL-E i Midjourney.
Právě těmto předním generátorům obrázků by se měl Imagen 3 vyrovnat. Následující grafy tzv. „Elo score“ ukazují, že je na tom jen o něco hůře než Midjourney V6 a citelně lépe než DALL-E nebo StableDifusion 3 (v grafu jako „SD 3", pozn. red.).
.jpg)
Zdroj: Google DeepMind
Níže můžete vidět posun v detailu obrázku rosy na květu růže od modelu Imagen 2.
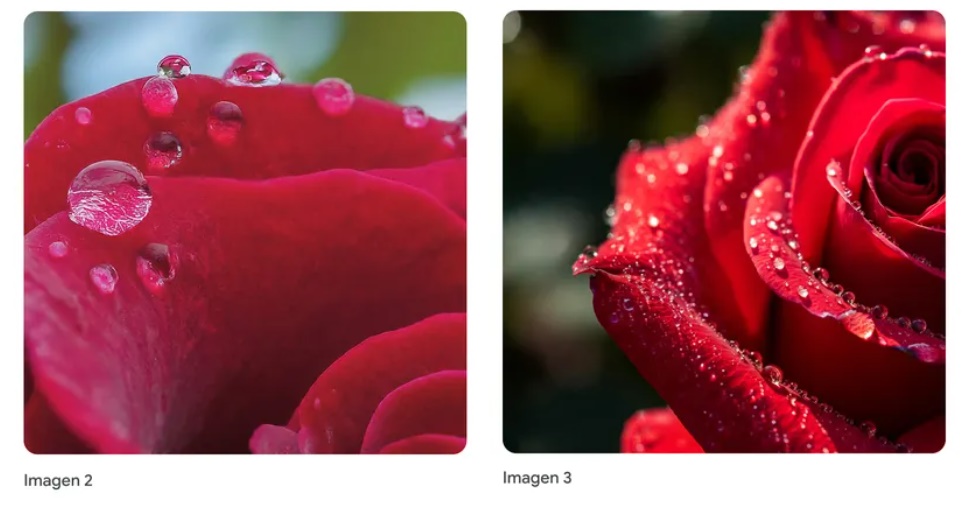
Zdroj: Google blog
A ve videu níže jsou představené funkce Imagen 3 podrobně.
Podobně jako DALL-E umí i ladění detailů v již vytvořeném vizuálu. Prvně jmenovaný nástroj od OpenAI je ovšem v implementaci úprav dost svérázný a tvrdohlavý, tak uvidíme, jaká bude praxe u toho od Googlu. V tuto chvíli si to mohou vyzkoušet uživatelé placeného AI chatbota Gemini Advanced v angličtině. Údajně by ale měl být později omezeně dostupný i ve free verzi globálně.
Níže si můžete prohlédnout vytvořené obrázky s jejich prompty (po kliknutí na obrázek je zvětšíte).

Prompt: An animated image of a tiny dragon hatching from an egg in a sunlit meadow, surrounded by curious glowing butterflies. Vibrant colors, detailed scales. Zdroj: Google blog
.jpg)
Prompt: An image of a ball gown made of paper napkins in an elegant showroom. Zdroj: Google blog
.jpg)
Prompt: A photorealistic image of a breathtaking mountain vista with jagged peaks and snow-capped summits, bathed in the warm glow of a setting sun. Dramatic clouds, painted in vibrant hues of orange, pink, and purple, streak across the sky, casting long shadows across the rugged landscape.Zdroj: Google blog
.jpg)
Prompt: A vibrant abstract painting with the words 'Dream Big' splashed across the canvas in bold colors. Zdroj: Google blog





