
AI výzkumníkům Microsoftu omylem uniklo 38 terabajtů dat

Zdroj: Stock photos on Shutterstock
Výzkumníci společnosti Microsoft v oblasti umělé inteligence omylem odhalili 38 terabajtů citlivých dat včetně soukromých klíčů a hesel. Jedná se o dosud největší únik skutečně masivního množství dat, jenž dokazuje, že s daty svěřenými umělé inteligenci zachází lidé, kteří dělají stejné bezpečnostní chyby jako většina z nás.
O této události informoval startup Wiz Research, který zjistil, že tato data byla dostupná dlouhodobě na úložišti GitHub.
Jak k tomu došlo? Uživatelé GitHubu, který poskytoval otevřený zdrojový kód a modely AI pro rozpoznávání obrazu, byli instruováni, aby si modely stáhli z adresy URL úložiště Azure. Wiz Research ovšem zjistil, že tato adresa URL byla nastavena tak, aby udělovala oprávnění k celému účtu úložiště, čímž omylem vystavila další soukromá data.
Tedy vědci chtěli sdílet malinký výčet dat a nasdíleli úplně všechno. Microsoft tuto informaci potvrdil, když uvedl:
„Tento systém zjistil konkrétní adresu URL SAS identifikovanou Wizem v repozitáři 'robust-models-transfer', ale nález byl nesprávně označen jako falešně pozitivní. Hlavní příčina tohoto problému byla odstraněna a nyní je potvrzeno, že systém detekuje a správně hlásí všechny nadměrně poskytované tokeny SAS."
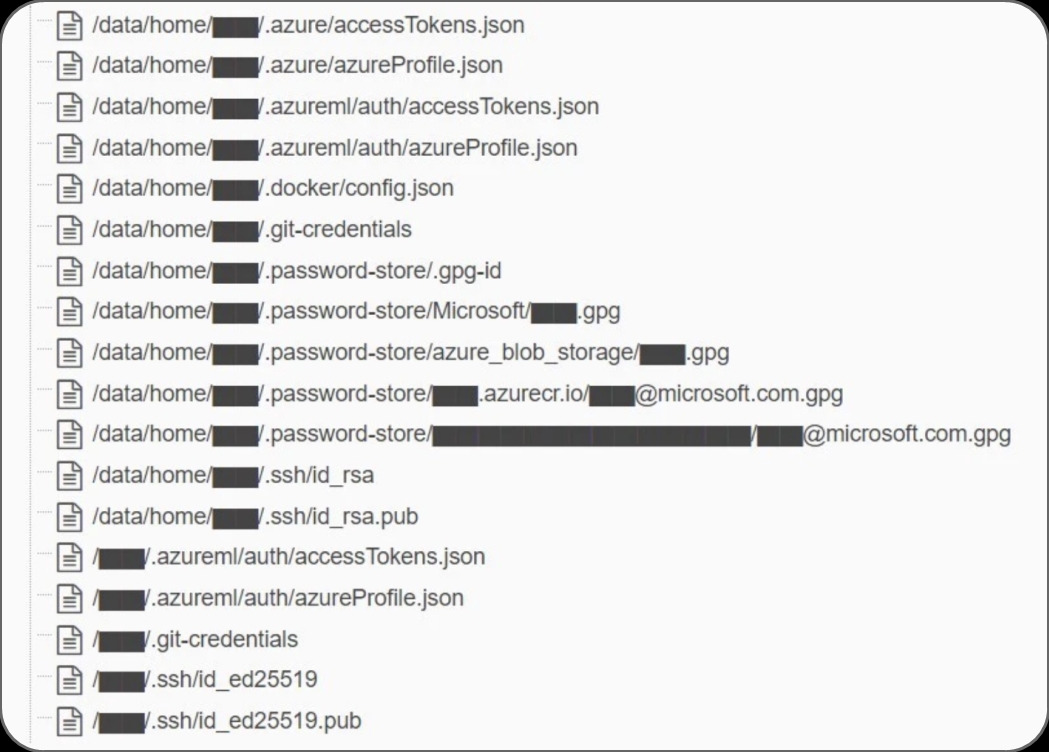
Ukázka malé části sdílených souborů s citlivými informacemi. Zdroj: Wiz Research
SAS znamená „shared access signature“ a tokeny SAS jsou mechanismus používaný službou Azure, který umožňuje uživatelům vytvářet sdílené odkazy poskytující přístup k datům na úložišti Azure. Přeloženo do lidské řeči Microsoft přiznává tento chybně sdílený link, ale nyní by žádný link s podobně otevřeným nastavením již sdílen být neměl.
Omylem sdílená data obsahovala citlivé osobní údaje, včetně hesel ke službám společnosti Microsoft, tajných klíčů a více než 30 tisíc interních zpráv od stovek zaměstnanců společnosti Microsoft přeposlaných přes Microsoft Teams. Jednalo se o 38 terabajtů. 1 terabajt se rovná 2014 gigabajtů, vynásobte si to 38x. Pokud šlo z velké části o textové soubory, je jejich množství jednoduše obrovské.
Wiz přitom komentoval i potenciální nebezpečí spojené s tím, že k datům byl poskytnut plný přístup, nikoliv v režimu „read only“. „To je obzvlášť zajímavé, když vezmeme v úvahu původní účel úložiště: poskytovat modely umělé inteligence pro použití v tréninkovém kódu. To znamená, že útočník mohl do všech modelů AI v tomto úložišti injektovat škodlivý kód a každý uživatel, který důvěřuje úložišti GitHub společnosti Microsoft, jím mohl být infikován," uvedl.
Nic takového se prý nestalo. Ukazuje to ovšem potenciální rizika spojená s provozem velkých AI modelů. V rámci denního provozu velkého jazykového modelu s desítkami až stovkami milionů uživatelů terabajty dat „tečou“ jinou rychlostí než při tréninku AI modelů. Ss tím pak může být spojeno i vyšší riziko úniku části z nich.
Mnoho velkých firem dosud odmítalo používání umělé inteligence, včetně ChatGPT od společnosti Open AI. V ní má majetkový podíl právě Microsoft, který je pochopitelně i jakousi záštitou bezpečnosti od velkého subjektu, protože spravuje nepředstavitelné množství dat už několik dekád. Součástí bezpečnosti prémiové nabídky pro firmy, ChatGPT Enterprise, je zejména příslib bezpečnosti dat opírající se i o data uložená na Microsoft Azure. Tento případ pak odhaluje, že ani to není 100% zárukou, a může dát AI skeptikům do rukou další protiargumenty, proč svá firemní data nevystavovat novým nebezpečím.




