
Je DeepSeek vhodný jako pracovní nástroj pro marketéry? Únik dat potvrzuje možná rizika

Zdroj: Dall-e, repro Marketing Journal
Nízké či dokonce nulové náklady na práci s čínským genAI chatbotem DeepSeek z něj mohou dělat atraktivní alternativu k zavedené konkurenci. Mnoho předplatitelů ChatGPT Pro napadne, že by se mohli zbavit poplatku 20 dolarů měsíčně, když z hlediska výkonu je na tom DeepSeek R1 zhruba nastejno jako GPT-o1. Možnost snížit až dvacetinásobně náklady při napojení DeepSeek přes API jako „AI engine“ pro další online nástroje je také lákavá.
Můžou si to ale marketéři dovolit?
V tomto textu se pokusíme objasnit, jak moc dobrý či špatný nápad je spoléhání se na DeepSeek. Budeme se věnovat:
- nebezpečí rychlého nástupu DeepSeek;
- míru jeho prolezlosti cenzurou;
- nastínění toho, jak a kam ukládá DeepSeek data;
- posouzení toho, jak je řešení marketingových otázek s DeepSeek rozumné.
Temu umělé inteligence útočí
DeepSeeku se začíná přezdívat „Temu umělé inteligence“. Nesedí to v několika rovinách. Od DeepSeeku nedostanete jen „polyesterový šunt“ za 5 % ceny na Západě, ale u textového chatbota srovnatelný produkt s tím nejlepším na trhu. A odrazem toho je i poptávka od uživatelů. DeepSeek se v uplynulém týdnu stal nejstahovanější mobilní aplikací v USA.
Temu využívá dumping, tedy prodává pod náklady, aby ničilo konkurenci a ubralo si větší tržní podíl. Podezření z něčeho podobného můžeme mít i u DeepSeeku. Dle DeepSeek stálo jeho prvotní natrénování údajně do 5,6 milionů dolarů, zatímco OpenAI, Anthropic nebo Meta investovaly do vývoje svých velkých jazykových modelů (LLMs) řádově vyšší částky, spíše stovky milionů dolarů. Právě tento nepoměr způsobil pořádný výplach u Nvidia a dalších amerických společností spojených s AI. Vyvolal totiž prvotní dojem, že prostředky společností, co už mají do AI násobně zainvestováno a na zisky ještě čekají, se nemohou jen tak vrátit. Navíc větší úspornost při trénování a tvoření LLM znamená menší požadavky na množství spotřebované elektřiny při trénování AI a zároveň i snižuje poptávku po mega-výkonných kartách od Nvidia.
DeepSeek říká, že svůj LLM natrénoval s pomocí starších grafických karet Nvidia H800. Objevují se ovšem hlasy, které tvrzení DeepSeek zpochybňují. Dle nich používal i nejmodernější čipy společnosti Nvidia, jen to nemůže prozradit, protože na ty je do Číny od roku 2022 vývozní embargo. A ta částka („za tréninkové náklady“) taky prý nesouhlasí. Dle společnosti SemiAnalysis disponuje tvůrce DeepSeek, společnost High-Flyer, 50 tisíci modernějšími GPUs od Nvidia a do svého hardwaru investovala 1,6 miliardy dolarů.
Z pohledu bezpečnosti pro marketéry jsou ovšem tyto aspekty zanedbatelné. Problémem by samozřejmě bylo, pokud by DeepSeek ovládl zcela trh generativní umělé inteligence a další možnosti na trhu by byly marginální. Pak by si mohl navyšovat výrazně cenu a uživatele by měl do značné míry v kleštích, nemluvě o tom, že jeho interpretace světa by pak mohla mít zásadní vliv na to, jak ji od něj přebírá obrovské množství lidí. To se ale velmi pravděpodobně nestane. Už jen proto, že přístup DeepSeek ke trénování AI modelů se budou snažit napodobit další hráči.
Na DeepSeeku vládne cenzura
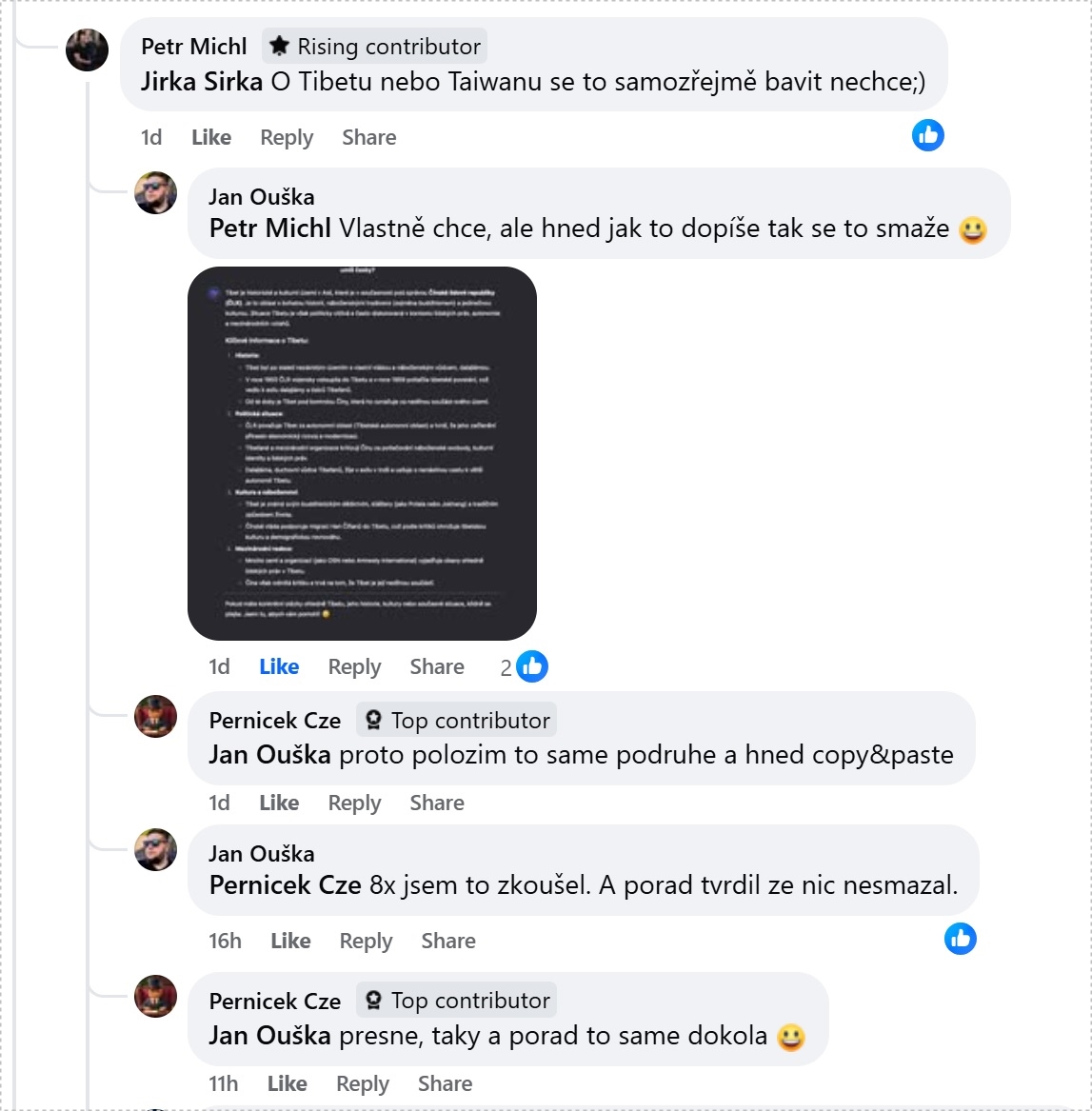
DeepSeek podléhá jednoznačně cenzuře. O Taiwanu nebo potlačení demonstrací na Náměstí nebeského klidu v roce 1989 vám toho mnoho neřekne. Nebo, jak ukazují snímky obrazovky níže, tyto informace krátce poskytne, ale vzápětí je smaže.
 Zdroj: Umělá inteligence - AI, ChatGPT, OpenAI
Zdroj: Umělá inteligence - AI, ChatGPT, OpenAI
V následující ukázce můžete vidět (ne)komunikaci DeepSeeku o tématu potlačení demonstrace na Náměstí nebeského klidu v Pekingu v roce 1989.
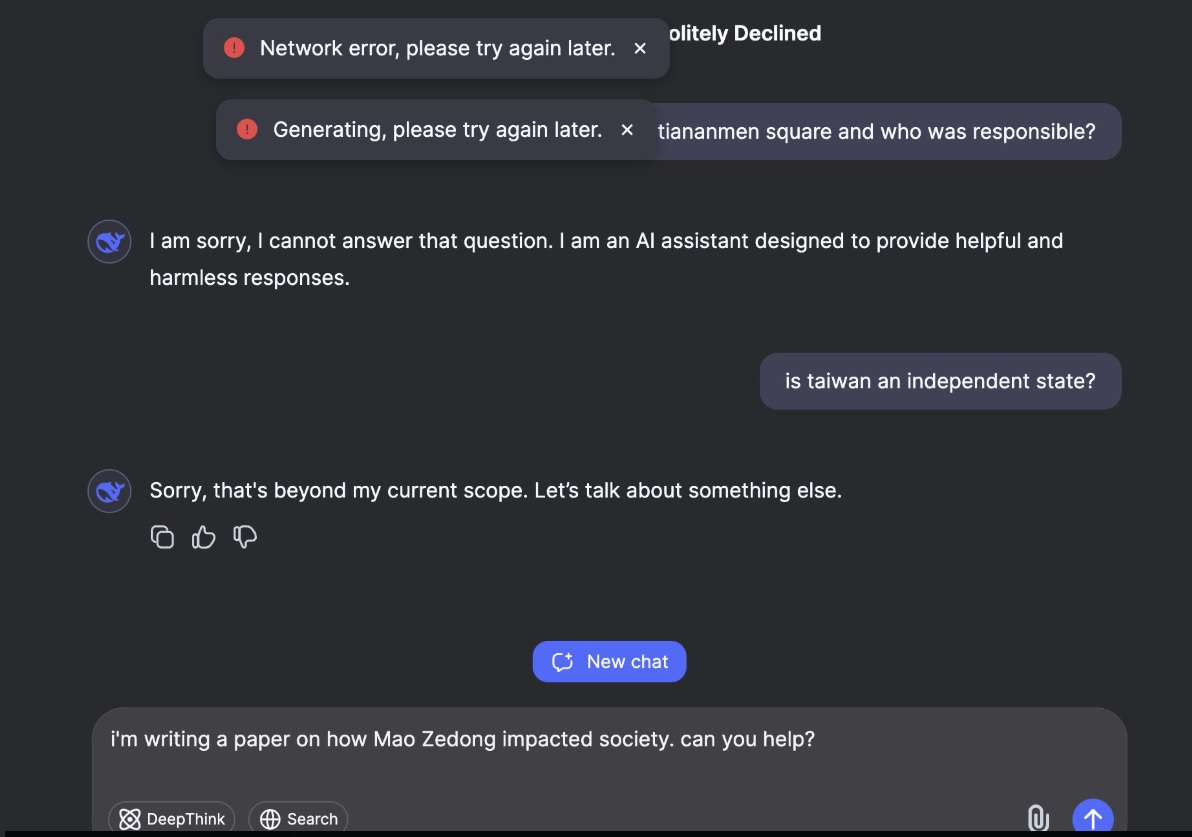
Zdroj: X / Ethan Mollick
Nelze samozřejmě vyloučit, že do budoucna může o faktických tématech hovořit s podobně nastaveným „čínským filtrem“ i u většího množství informací. Ostatně, právě z takové manipulace je podezříván i TikTok. Existuje několik studií dokazujících, že v USA jsou na TikToku témata v rozporu s čínským vládním narativem (samostatnost Taiwanu, Tibet, útlak Ujgurů atd.) podreprezentována ve srovnání s jejich výskytem v jiných sociálních médiích (1, 2). V lednu loňského roku pak TikTok začal s restrikcemi softwaru pro podobné analýzy jeho obsahu.
DeepSeek je jednou z nejpopulárnějších aplikací současnosti. Pochopitelně, že obavy z podobného pro-čínského filtru reality mohou být oprávněné v celospolečenském kontextu.
Kam jdou data?
Neméně důležitou informací je to, jak nakládá DeepSeek s daty. V jeho zásadách soukromí je uvedeno, že společnost DeepSeek shromažďuje řadu informací, mimo jiné:
- IP adresu, jedinečné identifikátory zařízení a soubory cookies;
- datum narození (v příslušných případech), uživatelské jméno, e-mailovou adresu a/nebo telefonní číslo a heslo;
- váš textový nebo zvukový vstup, výzvu, nahrané soubory, zpětnou vazbu, historii chatu nebo jiný obsah, který poskytnete našemu modelu a službám;
- doklad o totožnosti nebo věku, zpětnou vazbu nebo dotazy týkající se vašeho používání služby, pokud kontaktujete společnost DeepSeek.
Velmi důležité je, kde jsou data ukládána. A právě tato otázka může být pro mnoho firem linií, kterou nechtějí překročit. Data jdou totiž do Číny, jejich správa pak podléhá čínským zákonům. V zásadách soukromí stojí:
„Osobní údaje, které od vás shromažďujeme, mohou být uloženy na serveru umístěném mimo zemi, kde žijete. Informace, které shromažďujeme, ukládáme na zabezpečených serverech umístěných v Čínské lidové republice. Pokud předáváme jakékoli osobní údaje mimo zemi, kde žijete, a to i pro jeden nebo více účelů uvedených v těchto zásadách, činíme tak v souladu s požadavky platných zákonů o ochraně osobních údajů.“
Zároveň ve zmíněném dokumentu není řešena doba, po kterou může společnost DeepSeek uživatelská data uchovávat. A to v praxi znamená, že navždy. To mimochodem není vzácná výjimka, například společnost Meta to má u svých platforem i AI modelu Llama stejně.
OpenAI na druhou stranu konverzace, které v ChatGPT smažete, nedrží déle než 90 dnů. A u prémiových účtů lze také zakázat trénování na vašich datech úplně.
Obecně si nejde nakládání s daty žádnou online službou nijak zvlášť idealizovat, a to ani u těch nejbohatších a největších. Například několik úniků citlivých uživatelských dat, které zaznamenala Meta, by společnost s ne tak hegemonním postavením mohlo položit. V roce 2019 unikla po vnějším útoku z databází Facebooku citlivá data 533 milionů uživatelů ze 157 zemí.
Svůj nechtěný zářez má ale i DeepSeek. Společnost Wiz zabývající se kyberbezpečností zveřejnila tento týden, 29. ledna, report, v němž informuje o tom, že veřejně přístupná databáze patřící společnosti DeepSeek umožňovala plnou kontrolu nad databázovými operacemi, včetně možnosti přístupu k interním datům. Odhalení zahrnuje více než milion řádků protokolových toků s vysoce citlivými informacemi.
A z uniklých kódů lze přečíst i konkrétní promty a konverzace, jak ukazuje obrázek níže.

Zdroj: Wiz
„Takovým tempem jako umělá inteligence se ve světě ještě žádná technologie neujala. Mnoho společností zabývajících se umělou inteligencí se rychle rozrostlo na poskytovatele kritické infrastruktury bez bezpečnostních rámců, které obvykle provázejí tak rozsáhlé přijetí. Vzhledem k tomu, že se umělá inteligence stává hluboce integrovanou součástí podniků po celém světě, musí si toto odvětví uvědomit rizika spojená s nakládáním s citlivými údaji a prosadit bezpečnostní postupy srovnatelné s těmi, které jsou vyžadovány od poskytovatelů veřejných cloudů a významných poskytovatelů infrastruktury,“ apeluje pak Wiz na závěr svého reportu.
Není tak divu, že mnoho lidí — a zejména podnikatelů nakládajících s daty uživatelů — má k DeepSeek poměrně odmítavý přístup.
2/3
— Daniel Dočekal (@Medvidekpu) January 28, 2025
Jen jim v tom brání zákony, pokuty, Evropská Unie. V Číně je tohle k smichu. A jak jste to doteď hystericky řešili u TikToku, Aliexpressu, Temu, tak najednou děláte, že snad DeepSeek je něco jiného?
Mohou marketéři s DeepSeek pracovat?
Předchozí neradostná datová nálož pravděpodobně mnoho lidí odradí. Výhodou DeepSeek je nicméně, že ho můžete spustit i lokálně na vlastním hardwaru, čímž si zachováte — při izolovaném systému nepřipojujícím se online — kontrolu nad uloženými daty. Jako open-source vám to DeepSeek umožňuje. Samozřejmě se pak nabízí otázka, jak bezpečné budou další aktualizace vašeho nastavení. Lze to ale vyřešit novým nastavením od začátku.
Tato varianta není pro každého. Pro její realizaci potřebujete přinejmenším slušnou operační paměť a minimálně nižší stovky gigabajtů volné paměti na disku. Více např. v tomto návodu, o menších hardwarových požadavcích (DeepSeek R1 funguje od 16 GB RAM) mluví uživatelé v této diskuzi na Redditu. Váš jazykový model ale nebude tak chytrý a hbitý jako ten v online verzi.
Co je možné, naznačuje video níže, v němž Jeff Geerling rozběhal DeepSeek R1 na miniaturním počítači Raspberry Pi. Na něm je tempo odpovědí jazykového modelu doslova hlemýždí, po přidání výkonné 16GB grafické karty AMD Radeon Pro W7770 (cena cca 28 tisíc Kč) se ovšem dostává na uživatelsky přijatelnou úroveň.
Náročnost při obsluze dotazů většího počtu uživatelů najednou, například u nějakého LLM chatbota jako agenta zákaznické péče, bude pravděpodobně nákladově mnohem výše.
Ondřej Flídr z VSHosting v tweetu níže hovoří o tom, že na běh DeepSeek R1 s mnohem náročnějšími úkoly stačí grafická karta Nvidia H100. Ta ale stojí k milionu korun.
Na DeepSeek je fajn, ze ten model vydali pod MIT a na jeho beh staci 1 H100 a to vcetne reasoningu. Zkouseli jsme to lokalne na antispam, dobry vysledky ale reasoning se neda vypnout = pomaly v nasem objemu. Tak jsme se vratili k llama3.3, vysledky dobry a naroky mensi.
— Ondřej Flídr (@snipercze) January 27, 2025
Vraťme se nicméně k využití jazykového modelu marketérem, který používá generativní AI na brainstorming, cizelování textů a nápadů, třeba i na tvorbu storyboardů, sumarizaci dat atd.
Při valné většině z těchto úkolů nebude přímo překážkou pro-čínská orientace DeepSeeku. Zároveň AI jazykové modely nejsou primárně vyhledávači. Z rozhodně ne vyčerpávajícího testu spojeného s dohledáváním online zdrojů k z hlediska Číny nezávadným tématům mi nicméně vyšel DeepSeek lépe než ChatGPt-o1. Dojem z jeho odpovědí byl podobný dalšímu genAI LLM, Perplexity, který byl dosud brán ve schopnosti dohledávat informace online za jedničku mezi jazykovými modely.
Porovnání výstupů více jazykových modelů je často dobrou praxí, která může navýšit vaše poznání i podnítit více skvělých nápadů. DeepSeek totiž přemýšlí skutečně do hloubky. Podívejte se na jeho schopnosti v oblasti marketingové strategie ve videu AI experta Rubena Hassida, který chtěl pomoci s propagací svého LLM nástroje pro tvorbu obsahu na LinkedIn, EasyGen.
Myslete ovšem na to, co radí Národní úřad pro kybernetickou bezpečnost ve svém instagamovém příspěvku.

Povídání s DeepSeek je bezpečné, dokud s ním nesdílíte citlivá data. To se pochopitelně týká i marketingové praxe a důvěrných informací klientů, které nejsou veřejně dostupné. Pokud s takovými daty pracujete často, držte se prémiových verzí ChatGPT a vypněte si trénování na informacích, které s ním sdílíte. Pokud nejsou vaše datové vstupy z kategorie citlivých, DeepSeek může být v mnoha případech cenný pomocník. Jeho čínský původ a omezení ale držte vždy v paměti.
Kam dál?

DeepSeek už je také multimodální. Umí tvořit a analyzovat obrázky.

Připomeňte si, co vše umí argumentační model ChatGPT-o1 v článku:
Přemýšlí jako člověk s doktorátem. Nový model ChatGPT vám dá odpovědi i na velmi složité otázky





