
Nový agent Deep Research v ChatGPT má ušetřit hodiny práce na analýzách. Jeho přesnost je dosud nevídaná

Zdoj: OpenAI
U AI chatbotů platí zejména u dotazů na faktické informace heslo „Důvěřuj, ale prověřuj.“ Jsou skvělé v sumarizaci vám dodaných informací, ale když se spoléháte s faktickou odpovědí přímo na ně, můžete se dočkat drobných nepřesností i úplných halucinací. Tento týden představený agent Deep Research od OpenAI má nicméně být schopen rozsáhlých a fakticky přesných analýz, které obstojí i u vědeckého zkoumání.
Jedná se o AI agenta, kterému zadáte práci. On se doptá nadůležité detaily, aby zajistil, že přesně rozumí požadavku. Dokáže i pracovat s dodanými podklady od vás. Poté se pustí do vyhledávání informací, aby je ve výsledku propojil do závěru v podobě podrobného reportu.
Report není jen shrnutím existujících informací – místo toho aktivně hledá nové poznatky, propojuje je a vytváří komplexní analýzy, u nichž cituje použité zdroje. Pracuje přitom zhruba 5 až 30 minut. Unikátní vlastností je schopnost zpětného vyhodnocování, což znamená, že pokud Deep Research narazí na nesrovnalosti nebo neúplné informace, vrátí se zpět a provede dodatečné dotazy nebo nové vyhledávání.
Deep Research rozumí obrázkům i grafům a schématům, dokáže provádět numerické analýzy a vizualizovat data pomocí grafů v Pythonu.
Způsob jeho práce můžete vidět v následujícím ukázkovém videu, v němž Deep Research generuje report, který by se rozhodně mohl hodit i marketérům.
OpenAI v tiskové zprávě říká:
„Deep Research nezávisle objevuje, zdůvodňuje a konsoliduje poznatky z celého webu. Aby toho dosáhl, byl vycvičen na reálných úlohách vyžadujících použití prohlížeče a nástrojů Python pomocí stejných metod posilování učení, které stojí za OpenAI o1, naším prvním uvažovacím modelem. Zatímco o1 vykazuje působivé schopnosti v kódování, matematice a dalších technických oblastech, mnoho reálných úloh vyžaduje rozsáhlý kontext a shromažďování informací z různých online zdrojů. Deep Research staví na těchto schopnostech uvažování, aby tuto mezeru překlenul a umožnil mu řešit typy problémů, s nimiž se lidé setkávají v práci a každodenním životě."
Deep Research má najít uplatnění ve vědeckých aplikacích, ale i v každodenních činnostech. Přímo v tiskové zprávě si můžete porovnat odpovědi GPT-4o a Deep Research v oblastech podnikání, medicínského výzkumu, UX designu, obecných znalostí, ale také u nákupního rozhodnutí (koupě snowboardu nebo hledání „jehly v kupce sena“ (prezentováno jako vyhledávání seriálu na základě mlhavého naznačení části děje).
Sam Altman se na X pochlubil tím, jak v Japonsku marně hledal ke koupi model sportovního automobilu Honda NSX. Vzácného veterána na prodej nemohl online najít, ale Deep Research byl úspěšný.
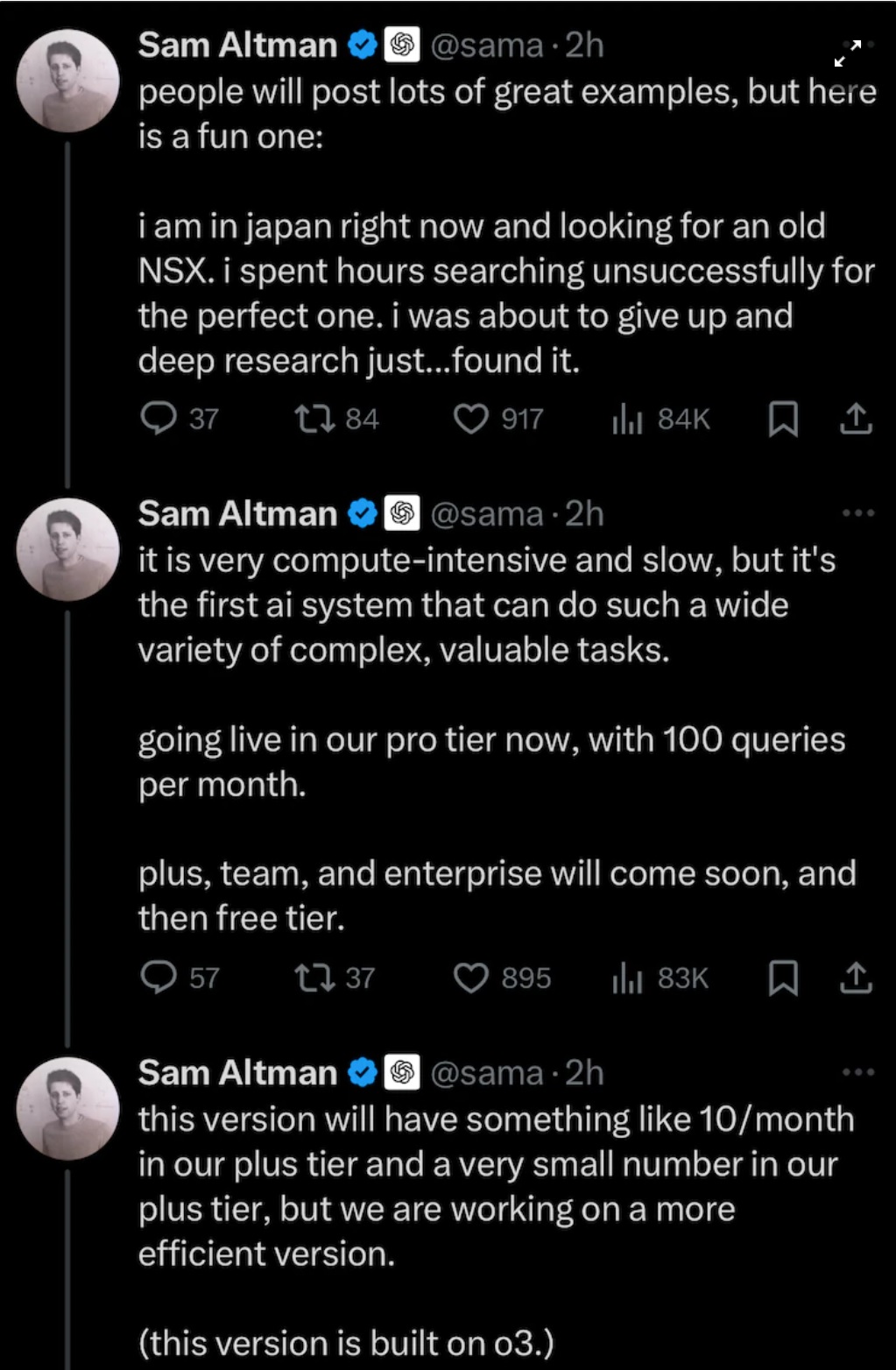
Zdroj: Sam Altman / X
Dosud nejblíž obecné umělé inteligenci
Deep Research operuje s pomocí jedné z verzí nového modelu o3. O něm Sam Altman na začátku roku v rozhovoru pro Bloomberg uvedl, že je dosud nejblíže tzv. obecné umělé inteligenci. Deep Research jako do značné míry autonomní jednotka je pak toho největší ukázkou.
Dle tweetů akademiků níže se to projevuje například tím, že Deep Research se chová jako člověk na stopě informacím, který si různé zdroje dokáže navzájem propojovat, a docházet na základě toho k vlastním názorům. Na rozdíl od nástroje NotebookLM od Googlu, který „jen" skvěle sumarizuje velké množství zdrojů.
OpenAI’s deep research is very good. Unlike Google’s version, which is a summarizer of many sources, OpenAI is more like engaging an opinionated (often almost PhD-level!) researcher who follows lead.
Look at how it hunts down a concept in the literature (& works around problems) pic.twitter.com/zAQSBrP2i7
OpenAI’s new AI agent “Deep Research” is like having a 24/7 assistant who immediately becomes an expert on any topic- then surpassing even the professor (like me!) or the subject-matter expert asking for help! It’s a super exciting & addictive yet very humbling experience to use!
— Derya Unutmaz, MD (@DeryaTR_) February 3, 2025
Jako skutečně podrobný ponor do výsledků Deep Research nabízíme například sdílené ChatGPT vlákno k promptu požadujícím prozkoumání dostupných výzkumných dokumentů AI nástroje DeepSeek s prosbou o odhad, kam se letos posune. Náleží k tweetu níže.
Insane.
Deep-Research is something truly special.
It conducted an expert level business and technical analysis on Deepseek's entire R&D history, and made **excellent** extrapolations.https://t.co/CkeM8ynVNq pic.twitter.com/Bpngwa6FB9
Jde o model, který je výpočetně velmi náročný, a proto je zatím dostupný jen v Pro verzi předplatného ChatGPT (toho za 200 dolarů měsíčně) s možností 100 dotazů za měsíc. Pracuje se nicméně na tom, aby v mnohem omezenější podobě byl k dispozici i v levnějších prémiových verzích ChatGPT Plus, Team a Enterprise.
Faktická spolehlivost je stále tématem
Kdybyste brali doslova vše výše popsané, implicitně by to mohlo vést například k rozpuštění řady vědeckých týmů či propuštění některých jejich členů. Samotná OpenAI ovšem sama přiznává limity Deep Research. Tento agent absolvoval tzv. Humanity’s Last Exam — test, který testuje umělou inteligenci v širokém spektru subjektů na otázky expertní úrovně. Skládá se z více než 3 000 otázek s výběrem odpovědi a krátkých odpovědí z více než 100 oborů od lingvistiky přes raketovou vědu, klasiku až po ekologii.
Deep Research v něm dosáhl nového maxima: 26,6 % přesnosti. „Ve srovnání s OpenAI o1 se největší nárůst objevil v chemii, humanitních a společenských vědách a matematice. Deep Research předvedl přístup podobný lidskému tím, že v případě potřeby efektivně vyhledával specializované informace,“ popisuje Open AI na svém blogu.

Zdroj: OpenAI
Jedná se o skokové zlepšení, ale asi nejen autora tohoto textu napadne, proč velké jazykové modely, co přečetly snad vše na světě, měly dosud výsledky v nižších jednotkách procent.
Deep Research také ovládl test GAIA, veřejný benchmark, který hodnotí umělou inteligenci na základě otázek, které vyžadují soubor základních schopností, jako jsou uvažování, práce s více modalitami, prohlížení webových stránek a obecně znalost používání nástrojů. V něm dosáhl na průměrné skóre 72, 57 %, přičemž předchozí nejlepší výsledek předstihl bezmála o 10 procentních bodů.
Pro doplnění dodáváme ukázku z aktuální studie organizace NewsGuard, která testovala schopnost 10 nejpopulárnějších AI chatbotů odpovídat na dotazy z oblasti zpravodajství. V médiích se mluvilo zejména o tom, že DeepSeek obstál v tomto testu jen z necelých 17 %. V 83,3 % případů nedokázal na dotazy odpovědět nebo v nich říkal chybné informace. Mnohem méně se ale zdůrazňovalo, že tento „fail rate“ byl u 7 z 10 testovaných chatbotů alespoň 60 %, a nejlepší pak měl skóre 30 %.
Mimo DeepSeek nejsou bohužel další LLMs jmenovány, mezi testovanými byly modely ChatGPT-4o od OpenAI, Smart Assistant od You.com, Grok-2 od xAI, Pi od Inflection, le Chat od Mistral, Copilot od Microsoftu, Meta AI od Meta, Claude od Anthropic, Gemini 2.0 od Googlu a Perplexity.
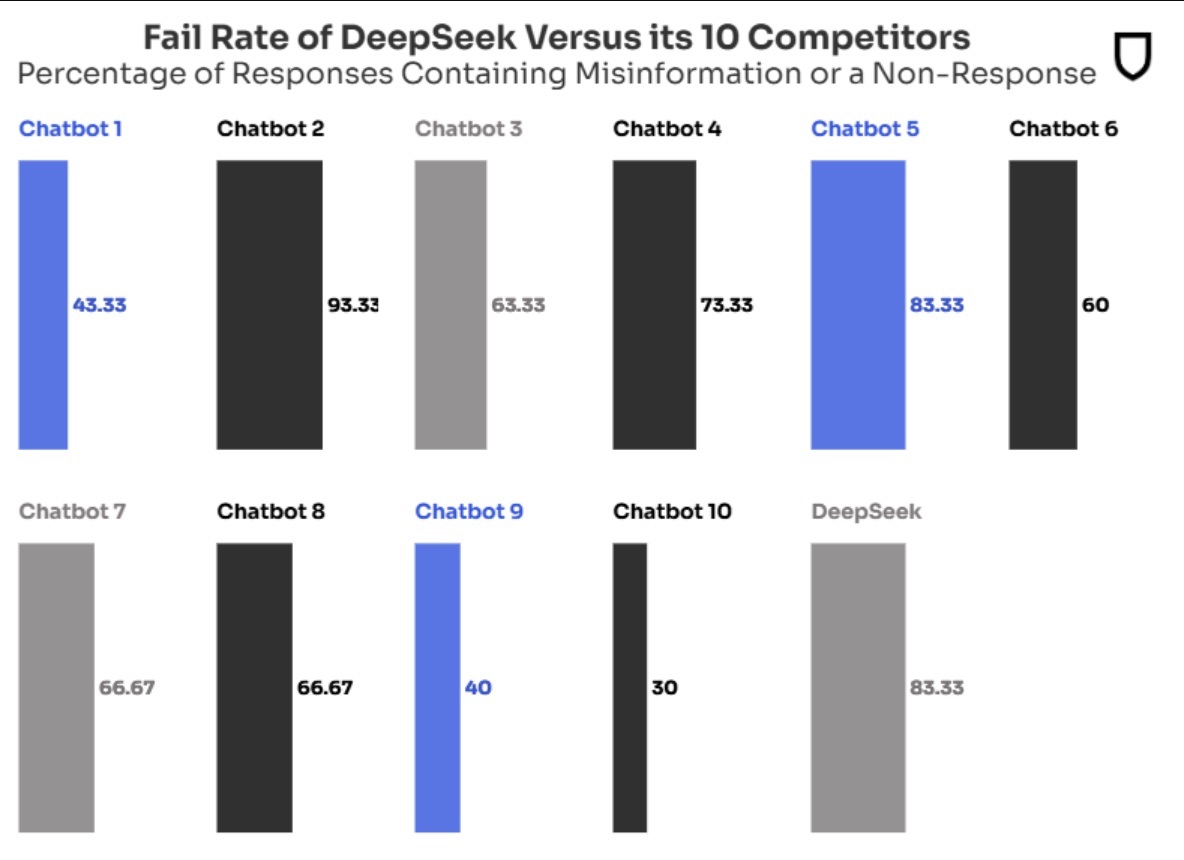
Zdroj: NewsGuard
Z těchto testů je zřejmé, že AI chatbotům nelze v přesnosti věřit, nebo pouze pracovat s tím, že si občas něco vymyslí. V některých oblastech evidentně selhávají. Deep Research má být novým lídrem, který to dělá nejméně. Je ale otázka, jak třeba přistupovat k vědeckým reportům s chybovostí na úrovni nižších desítek procent. Open AI navíc přiznává, že i Deep Research má tu a tam halucinace. Potíží je u něj samozřejmě i to, že u komplexních reportů s vlastními závěry je přes uvedené zdroje velmi pracné ověřovat, kde v rozsáhlém dokumentu je chyba. Přesto může být Deep Research velmi užitečným nástrojem, a to i pro marketéry, kteří chtějí například znát lépe část trhu nebo chování zákazníků.
Tip redakce

Nezapomeňte na nástroj Googlu, který byl uveden loni v říjnu. NotebookLM může být neúnavným studijním parťákem, který vás provede informacemi až z 50 nahraných zdrojů. Jeho funkce audio přehledů v sobě nese příslib podcastové revoluce.




