Uniklý interní dokument odhaluje strach v Googlu: v oblasti AI ho převálcuje open-source hnutí

Zdroj: Stock photos on Shutterstock
Google v boji na AI frontě velkých jazykových modelů prohrává s autorem ChaGPT, společností Open AI, a v nově uniklém dokumentu to přiznává. Má ovšem ještě jednu větší obavu: jeho výhoda obřího technologického giganta s velkým množstvím vývojářů, kapitálu a technologického hardwaru není v oblasti velkých jazykových modelů (LLM) tak velkou výhodou. Síla open-source hnutí ukazuje, že by mohla zamést s Googlem, Open AI a dalšími velkými hráči.
Uniklé memo k tomu říká:
„Naše modely si sice stále udržují mírný náskok, pokud jde o kvalitu, ale rozdíl se překvapivě rychle zmenšuje. Modely s open-source kódem jsou rychlejší, přizpůsobitelnější, soukromější a výkonnější.
Se 100 dolary a 13 miliardami parametrů zvládnou věci, se kterými my zápasíme při 10 milionech dolarů a 540 miliardách parametrů. A dělají to v řádu týdnů, nikoli měsíců."
Proč velikost na sílu open-source hnutí nestačí
Dokument vyjmenovává další důvody, proč nemá Google ani další velcí hráči proti open-source hnutí výhodu. Není to rozhodně jen teoretizování. V březnu 2023 získala open source komunita uniklý kód velkého jazykového modelu od společností Meta s názvem LLaMA. Doslova za pár týdnů pak open-source komunita vyvinula klony LLM Googlu, Bard, a LLM od Open AI, ChatGPT. Asi nejznámějším z nich je přitom Dolly.
Uniklý dokument to rozvádí:
„Na začátku března se open source komunitě dostal do rukou první skutečně schopný model, když na veřejnost unikl LLaMA od společnosti Meta. Neměl žádné instrukce ani konverzační ladění, ani RLHF (vysvětlení dále – pozn. red.). Přesto komunita okamžitě pochopila význam toho, co dostala. Následoval obrovský příliv inovací, mezi významnými událostmi byly jen dny...
A jsme tady, sotva o měsíc později, a existují varianty s laděním instrukcí, kvantizací, zlepšením kvality, multimodalitou, RLHF atd...
A co je nejdůležitější, vyřešili problém škálování do té míry, že si s ním může každý pohrát. Mnoho nových nápadů pochází od obyčejných lidí. Vstupní bariéra pro trénink a experimentování klesla z celkového výkonu velké výzkumné organizace na jednoho člověka, jeden večer a a jeden silný notebook."
Zmíněná open-source komunita dokázala, že umí 2 zásadní věci:
Instruction tuning
Proces vylepšování jazykového modelu, který ho dokáže upravit pro specifické použití, pro které nebyl původně trénován.
Reinforcement learning from human feedback (RLHF)
Při této technice lidé dávají hodnocení výstupům jazykového modelu, a on se tak učí, co je pro lidi nejuspokojivějším výstupem.
RLHF je tím, co tak zlepšilo CHatGPT. Do rozsáhlého testování byli zahrnutí například pracovníci z Keni za 2 dolary na hodinu. Ani tato levná práce ale nenahradí tisíce zkušených IT nadšenců, kteří chtějí vylepšovat konkrétní LLM zadarmo.
Nadšení dobrovolníci můžou mít i lepší data
Když se vyvíjel ChatGPT nebo Bard, hledali odpovědi na různé otázky a odpovědi na stránkách jako Wikipedia, ale i Quora nebo Reddit. Při tvorbě výše zmíněné Dolly 2.0 byl využit jiný Q&A dataset od Databricks, na kterém se ovšem podílely tisícovky profesionálů, kteří jednoduše mohli odpovídat sofistikovaněji než lidé na Redditu.
Právě AI LLM model zaměřený na nějakou profesní oblast může být ze stejného důvodu schopnější než to, co nabízí Google nebo OpenAI. A navíc případ Dolly 2.0 ukazuje, že tvorba něčeho takového může trvat týdny, ne měsíce nebo roky.
Když nezačínáte od nuly, můžete už jen vylepšovat
Proces práce v open-source hnutí je ve velkém založený na vylepšování už dostatečně robustního kódu. A tím je třeba uniklý LLaMA, který pak jde vylepšovat velmi rychle s pomocí technik jako LoRA (Low-Rank Adaptation of Large Language Models), které snižují počet trénovatelných parametrů pro navazující úlohy, a to až v násobkách tisíců. To proces urychluje a zároveň snižuje jeho hardwarovou náročnost.
Memo k tomu říká:
„…při trénování obřích modelů od nuly se zahodí nejen předtrénování, ale i všechna iterační vylepšení, která byla provedena navíc. Ve světě open-source netrvá dlouho, než tato vylepšení převládnou, takže úplné přeškolení je extrémně nákladné.
Měli bychom se zamyslet nad tím, zda každá nová aplikace nebo nápad skutečně potřebuje zcela nový model.
...Z hlediska počtu vývojářských hodin totiž tempo zlepšování těchto modelů značně převyšuje to, co můžeme udělat s našimi největšími variantami, a ty nejlepší (open-source LLM modely, pozn. red.) jsou již z velké části k nerozeznání od ChatGPT."
Nejlepší strategií je naskočit na vlnu open-source i v oblasti AI
Celé memo podrobně vyjmenovává to, v čem je lepší open-source systém proti closed-source systému — tedy tomu, kdy za vývojem stojí zaměstnanci konkrétní organizace. Závěr neznámého autora je přitom jednoznačný: na open-source systém nikdo nemá. Z pohledu Googlu je nemožné být ve sféře LLM modelů hybatelem inovací a zároveň je vlastnit.
Radou je pak jít s proudem a open-source ovládnout. Minimálně u také open-source prohlížeče Chrome a mobilní operačního systému Android se to totiž Googlu už podařilo. V praxi by pak Google vypouštěl své AI projekty na open-source platformě, kterou by vlastnil.
Tip redakce
Zdroj: prezentace Jana Romportla na WebTop100
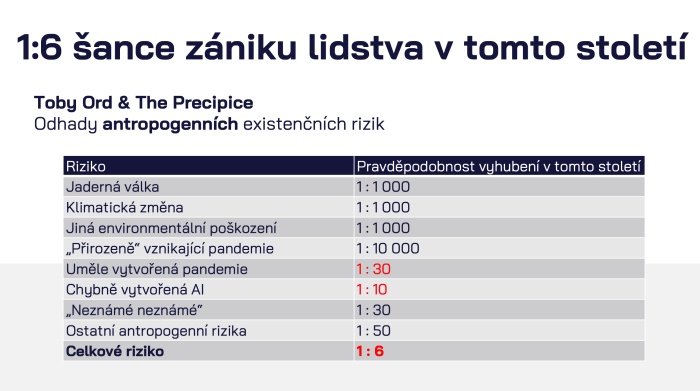
Dost možná vám právě přečtený článek přišel jako dobrá zpráva. Lidé často fandí Davidům proti Goliášům a s velkými korporacemi, které měly dlouho hlavní slovo, nemají při jejich pádu příliš slitování. Při rozvoji umělé inteligence, obzvláště pak velkých jazykových modelů, je ale nutné brát v potaz i bezpečnost. Právě LLM jsou nejblíže tzv. obecné umělé inteligenci (AGI) a její možná nebezpečí zahrnují i zánik lidstva.
Přečtěte si o tom více v článku Jan Romportl na WebTop100: AGI přichází a my na to nejsme připraveni.